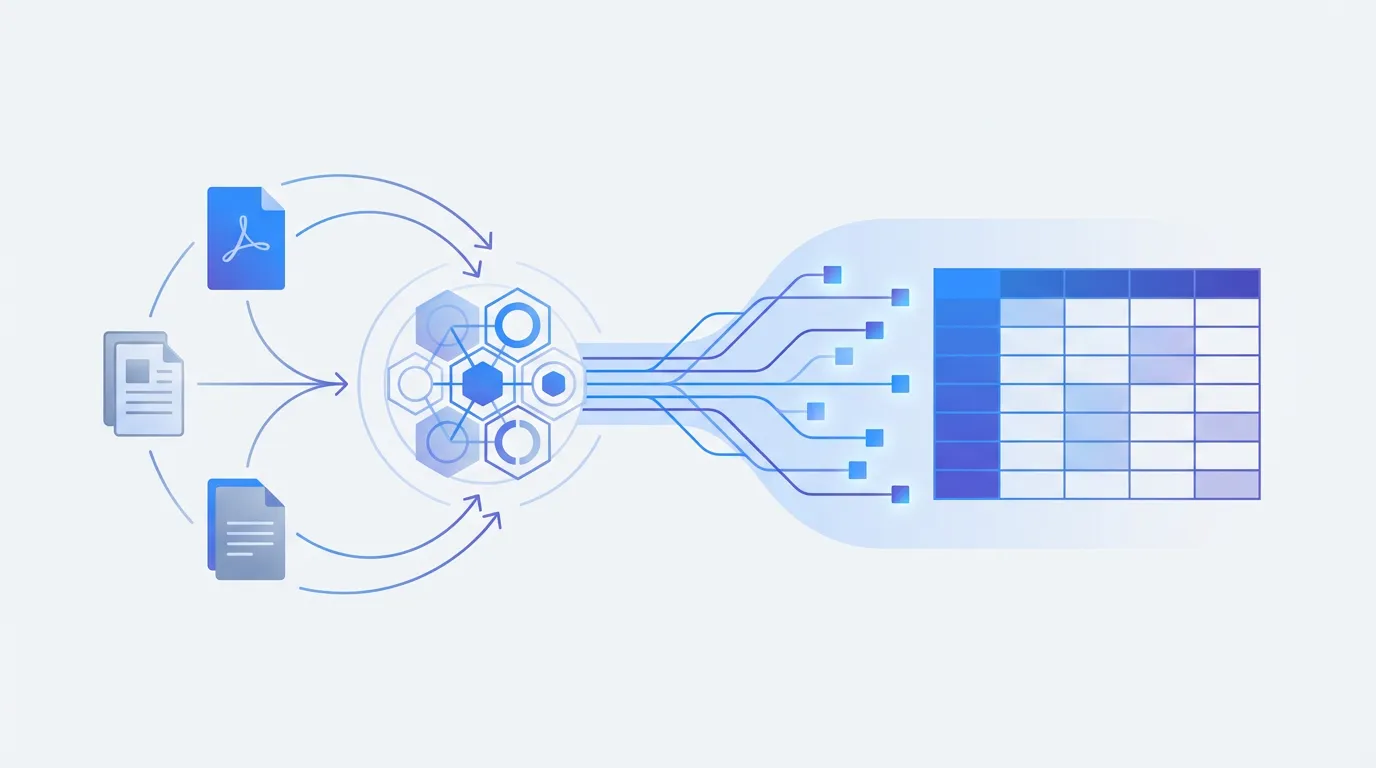
- -You don't need Python or coding skills to extract structured data from PDFs — several no-code tools handle it visually.
- -Manual copy-paste is the default for most teams, but it doesn't scale beyond a handful of documents per day.
- -Template-based tools (like Docparser) work for uniform documents but break when layouts change.
- -AI-powered no-code extraction (like Parsli) handles any PDF layout — invoices, receipts, bank statements, reports — without per-template configuration.
- -Define your fields once, upload your PDFs, and get structured data in Excel, CSV, or JSON. Try the free PDF to Excel converter →
You have 50 PDF invoices and you need the vendor name, invoice number, and total from each one in a spreadsheet. You're not a developer. You don't know Python. You don't have time to learn a programming language just to pull data out of documents you can read with your own eyes.
The good news: you don't need code to extract data from PDFs. The landscape of no-code extraction tools has matured significantly, and the best options use AI to understand document layouts — meaning you don't need to draw boxes around fields or write parsing rules. You just tell the tool what fields you want, upload your PDFs, and get structured data back.
This guide compares three approaches to no-code PDF data extraction — from manual methods to AI-powered tools — so you can choose the right one based on your document volume, layout variety, and accuracy needs.
73%
Of businesses still extract PDF data manually
15 min
Avg manual time per document
< 10s
AI extraction per document
0 lines
Code required with Parsli
What is no-code PDF data extraction?
No-code PDF data extraction means pulling specific fields — names, dates, amounts, tables, addresses — from PDF documents into structured formats like Excel, CSV, or JSON without writing any code. Instead of programming extraction rules, you use visual tools: drag-and-drop schema builders, point-and-click field selection, or AI that automatically identifies the fields you're looking for.
For example, if you need to extract vendor name, invoice number, date, and total from 100 invoices, a no-code tool lets you define those four fields visually, upload all 100 PDFs, and download a spreadsheet with 100 rows of structured data — no Python, no regex, no command line.
Why copy-paste from PDFs doesn't scale
Manual copy-paste is how most non-technical users extract PDF data today. It works, but it falls apart as volume or complexity grows.
- Time compounds fast — Extracting 5 fields from one PDF takes 5-10 minutes. Multiply by 50 documents and you've lost an entire day. That's a day you're not spending on analysis, decision-making, or customer-facing work.
- Errors accumulate silently — A transposed digit, a skipped field, a row pasted in the wrong place. At low volumes, these errors are rare. At 50+ documents, the 2-5% error rate means multiple incorrect records every batch.
- PDFs fight back — Some PDFs don't allow text selection. Scanned PDFs contain images of text, not actual text. Tables copy as jumbled text instead of structured rows. Each edge case requires a different manual workaround.
- No repeatability — If you extract the same type of document every month, you're doing the same manual work every month. There's no way to 'save' your process for next time.
- It's not delegatable — Training someone else to extract data correctly from your specific documents takes time, and their error rate during the learning curve makes the data unreliable.
How to extract PDF data without code: 3 methods compared
| Approach | Technical Skill | Accuracy | Layout Flexibility | Cost | Best For |
|---|---|---|---|---|---|
| Manual copy-paste | None | Medium (95%) | Any (human adapts) | Free (labor cost) | Under 10 docs/month |
| Template-based tools | Low | High on matched templates | Low (one template per layout) | $30-100/month | Uniform documents |
| AI-powered extraction (Parsli) | None | High (97-99%) | High (any layout) | Free tier available | Any volume or format |
Method 1: Manual copy-paste
Open the PDF, highlight the text you need, copy it, switch to your spreadsheet, paste it, clean up the formatting, repeat. This is the starting point for most teams, and it works for small batches of simple, text-selectable PDFs.
- When it works: Under 10 documents per month, all digital (not scanned) PDFs, simple field extraction (no tables), and when accuracy can be spot-checked manually.
- When it breaks: More than 10 documents/month, scanned or image-based PDFs, table extraction needed, multiple people need to extract from the same document types, or when data quality matters for downstream systems.
Method 2: Template-based extraction tools
Tools like Docparser and some versions of Parseur use a template approach: you upload a sample document, draw boxes around the fields you want to extract, label them, and save the template. Future documents with the same layout are processed automatically against that template.
- Pros: No coding required, high accuracy on documents that match the template exactly, visual setup process that business users can manage.
- Cons: You need a separate template for each document layout. If you process invoices from 30 vendors, you need 30 templates. When a vendor changes their invoice format, the template breaks and needs to be recreated. Doesn't handle scanned documents well.
Template-based tools are a good fit if you process the same document from the same source repeatedly — like a monthly bank statement from one bank. For varied layouts (multiple vendors, multiple document types), AI-powered extraction saves significant setup and maintenance time.
Method 3: AI-powered extraction with Parsli
Best For
Non-technical users who process PDFs from multiple sources with different layouts — invoices from various vendors, bank statements from different banks, or mixed document types.
Key features
- No-code schema builder — define fields visually, no templates to draw
- AI understands document layouts, not just coordinates
- Handles scanned PDFs, photos, and digital documents
- Extracts tables as structured arrays
- Export to Excel, CSV, JSON, or Google Sheets
Pros
- + One schema works across all layouts — no per-vendor templates
- + True no-code — no drawing boxes, no regex, no scripting
- + Built-in OCR for scanned documents
- + 30 free pages/month
Cons
- - Cloud-based (requires internet connection)
- - Free tier limited to 30 pages/month
Should you use Parsli?
If you need to extract data from PDFs that come in different layouts and you don't want to write code or maintain templates, Parsli is the simplest path from PDF to structured data. Try it free with no sign-up.
AI-powered extraction is fundamentally different from template-based tools. Instead of matching coordinates on a page, the AI reads the document the way a human would — understanding that 'Total Due' and 'Amount Payable' mean the same thing, and that the number next to it is the value to extract. This means one schema works across different layouts without per-source configuration.
Define your extraction schema
In Parsli's visual schema builder, add the fields you want to extract. For invoices: vendor_name, invoice_number, date, total. For bank statements: transaction_date, description, amount, balance. Name each field, set its type (text, number, date, currency), and mark repeating groups like line items.
Upload your PDFs
Drag and drop your PDF files — one at a time or in bulk. Parsli accepts digital PDFs, scanned PDFs, and even photos of documents. You can also set up email forwarding to process incoming documents automatically.
Review and export structured data
Parsli shows extracted data with confidence scores for each field. Review any flagged values, then export to Excel, CSV, JSON, or push directly to Google Sheets. Each document becomes a structured row in your spreadsheet — no copy-paste required.
Free PDF to Excel Converter
Upload any PDF and get structured data in an Excel spreadsheet — no code, no sign-up, no templates to configure.
Try it freeTired of copy-pasting from PDFs? Parsli extracts data from any PDF layout — no code, no templates. 30 free pages/month.
Use cases for no-code PDF extraction
1. Finance teams processing vendor invoices
AP teams receive invoices from dozens of vendors, each with a different PDF layout. Without code, they can define an invoice schema once in Parsli — vendor name, invoice number, date, line items, total — and extract from any vendor's format. The output goes to a Google Sheet for tracking or directly to QuickBooks via Zapier.
2. Operations teams digitizing paper forms
Many industries still use paper forms — inspection reports, intake forms, field surveys. Teams scan these forms to PDF and need the data in a database or spreadsheet. Parsli's OCR handles scanned documents, extracting form field values into structured data without requiring the operations team to learn any technical tools.
3. Research and analysis from PDF reports
Analysts who work with industry reports, regulatory filings, or competitor data in PDF format need to extract tables, key metrics, and narrative data points. Instead of reading each report and typing numbers into a spreadsheet, they define a schema for the data points they need and let the AI pull them from each report consistently.
Best practices for no-code PDF extraction
1. Start with a clear schema before uploading
Before uploading your first PDF, list exactly which fields you need and what format each should be in. 'Date' should be a date type (not text), 'Total' should be a currency/number type. A well-defined schema improves extraction accuracy and ensures your output is immediately usable in downstream systems without manual cleanup.
2. Test with diverse samples
Don't test with just one PDF. Upload 5-10 documents that represent the full range of layouts you'll encounter — different vendors, different formatting styles, scanned vs. digital. This validates that your schema works across your actual document variety, not just the cleanest example.
3. Use confidence scores to prioritize review
AI extraction isn't perfect — some fields on some documents will be uncertain. Instead of reviewing every extracted value, sort by confidence score and review only the low-confidence fields. This gives you human-verified accuracy where it matters without spending time checking values the AI is already confident about.
Common mistakes to avoid
1. Extracting too many fields at once
It's tempting to create a schema with 20+ fields to 'capture everything.' But more fields means more values to review, more potential errors, and slower processing. Start with the 5-7 fields you actually need for your immediate use case. You can always add more fields later as your confidence in the tool grows.
2. Assuming all PDFs are the same
Even documents of the same type (invoices, reports) can vary dramatically in layout. If you test on one vendor's invoice and assume extraction will work for all vendors, you'll be surprised when a different layout produces unexpected results. Always test across your real document variety before committing to a production workflow.
3. Skipping the review step for critical data
No-code tools make extraction feel effortless, which can lead to blind trust in the output. For data that feeds into financial systems, compliance reports, or customer-facing outputs, always include a review step — even if it's just a quick scan of low-confidence values. Automation should eliminate tedious work, not eliminate quality control.
From PDF to structured data — without writing a single line of code
Extracting data from PDFs used to require Python scripts, regex patterns, and hours of debugging. Today, non-technical users can define a schema visually, upload documents, and get structured data in seconds. The key is choosing the right tool for your layout variety — template-based tools for uniform documents, AI-powered tools like Parsli for varied layouts.
Start with the free PDF to Excel converter to see no-code extraction in action on your own documents. If you process invoices, try the invoice parser. For receipts, use the receipt scanner. Each tool demonstrates the same underlying AI extraction — just tuned for different document types.
Stop copying data out of documents manually.
Parsli extracts structured data from PDFs, invoices, and emails — automatically. Free forever up to 30 pages/month.
No credit card required. · Or book a demo call
Frequently Asked Questions
Do I really not need any coding skills?
Correct. Parsli's schema builder is entirely visual — you name fields, set their types, and the AI handles extraction. There's no code, no regex, no command line involved. If you can fill out a web form, you can use Parsli.
How does no-code extraction compare to Python-based extraction?
Python-based extraction (using libraries like pdfplumber or tabula) gives you more control but requires programming skills and per-layout scripting. No-code AI extraction trades some customization for massive ease of use — one schema works across layouts, no debugging required. For most business users, no-code AI extraction is more accurate and faster to set up than Python.
Can I extract tables from PDFs without code?
Yes. Parsli extracts tables as structured arrays — each row becomes an object with named fields. This works for invoice line items, bank statement transactions, report tables, and any other tabular data. You define the table fields in your schema, and the AI handles row detection and extraction.
What types of PDFs can I extract data from?
Parsli handles digital PDFs (text-based), scanned PDFs (image-based), photographed documents, Word documents, and Excel files. The built-in OCR handles scanned and photographed documents automatically — no preprocessing required.
How accurate is no-code extraction compared to manual?
AI-powered extraction typically achieves 97-99% accuracy on well-defined fields, compared to 95-98% for manual entry (humans make errors at scale). The advantage of AI extraction is consistency — it doesn't get tired, distracted, or rush through the last 20 documents before lunch.
What if the AI extracts a field incorrectly?
Each extracted field has a confidence score. Low-confidence values are flagged for review. You can correct any value in the Parsli dashboard before exporting. Over time, as you process more documents, you'll learn which fields and document types need manual review and which can be trusted automatically.
Related Resources
More Guides
How to Extract Line Items from Invoices Automatically
Learn 3 methods to extract line items from invoices — manual, Python, and AI-powered. Compare accuracy, speed, and cost for each approach.
Document ExtractionHow to Extract Data from Bank Statements (PDF to Excel)
Learn how to extract transactions, balances, and account details from bank statement PDFs. Compare manual, Python, and AI methods.
Data ConversionHow to Convert Receipts to Spreadsheet Data
Learn how to convert paper and digital receipts into structured spreadsheet data. Compare scanning apps, OCR tools, and AI extraction.
Talal Bazerbachi
Founder at Parsli